




模数转换
模拟信号
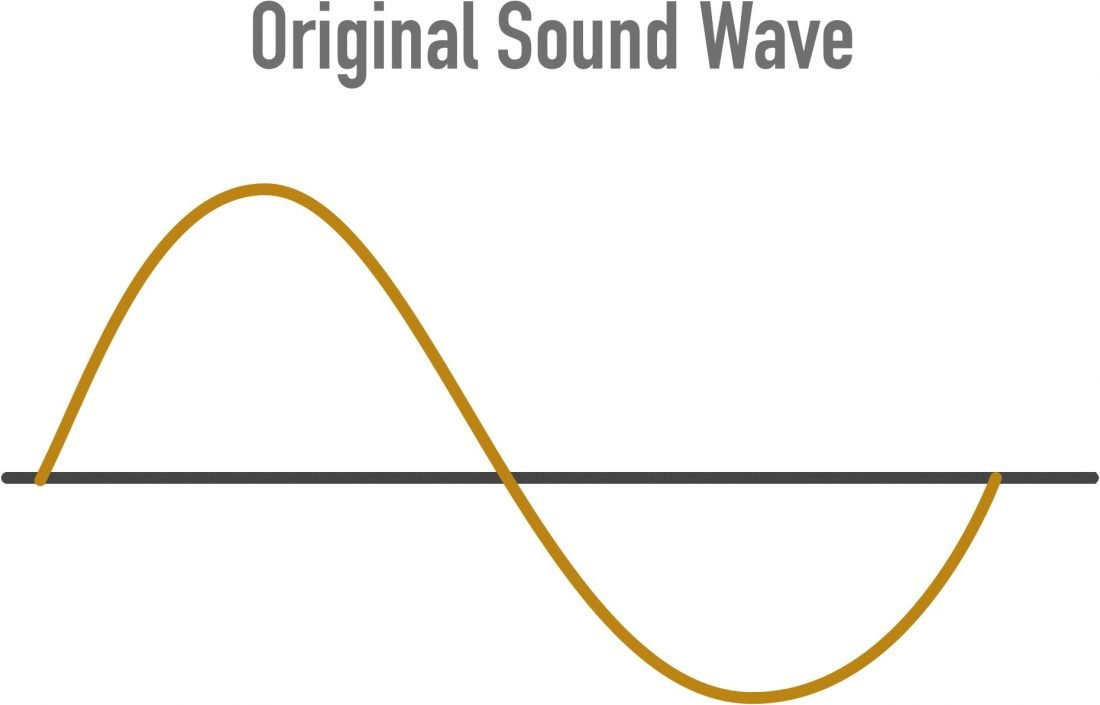
当声音产生时,它会产生在空气中传播的压力波。如果录音设备(例如麦克风)的膜片在附近,空气中的压力波会在膜片中产生振动。通过传感器的魔力,这种振动反过来会产生一个随着空气中的波连续变化的电信号。
这种连续的信号就是线性模拟信号,信号是随时间一直连续变化的
有许多模拟信号记录材质,如磁带、磁盘
采样率
为了存储与处理,模拟信号转数字AD 转换后即是我们现在常见的方式
通过抓取模拟信号的足够样本(采样),将连续时间信号转变成离散时间信号
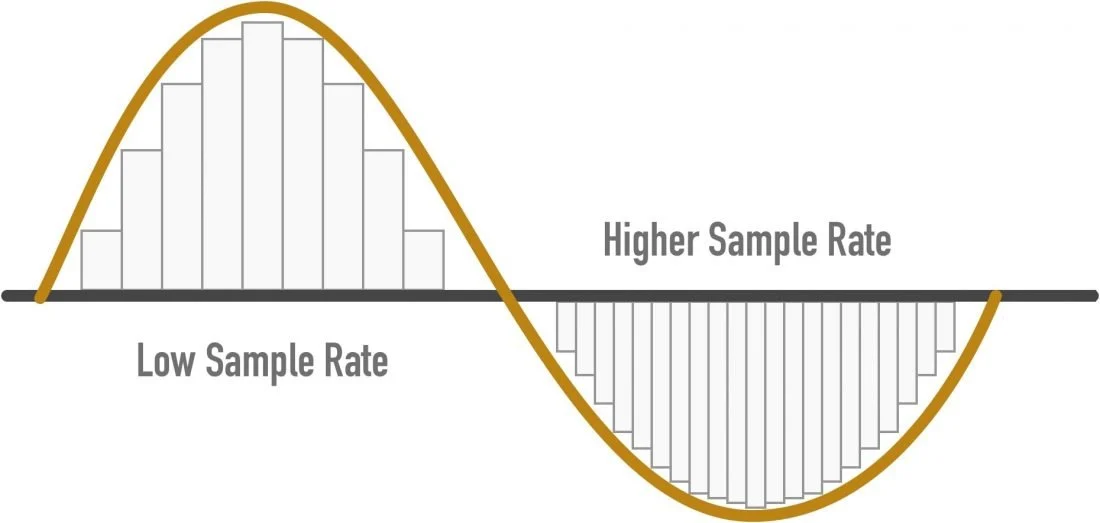
采样频率越高,精度就越高,就越接近原始声波,但只要数字化就会有损失,只是人耳不需要
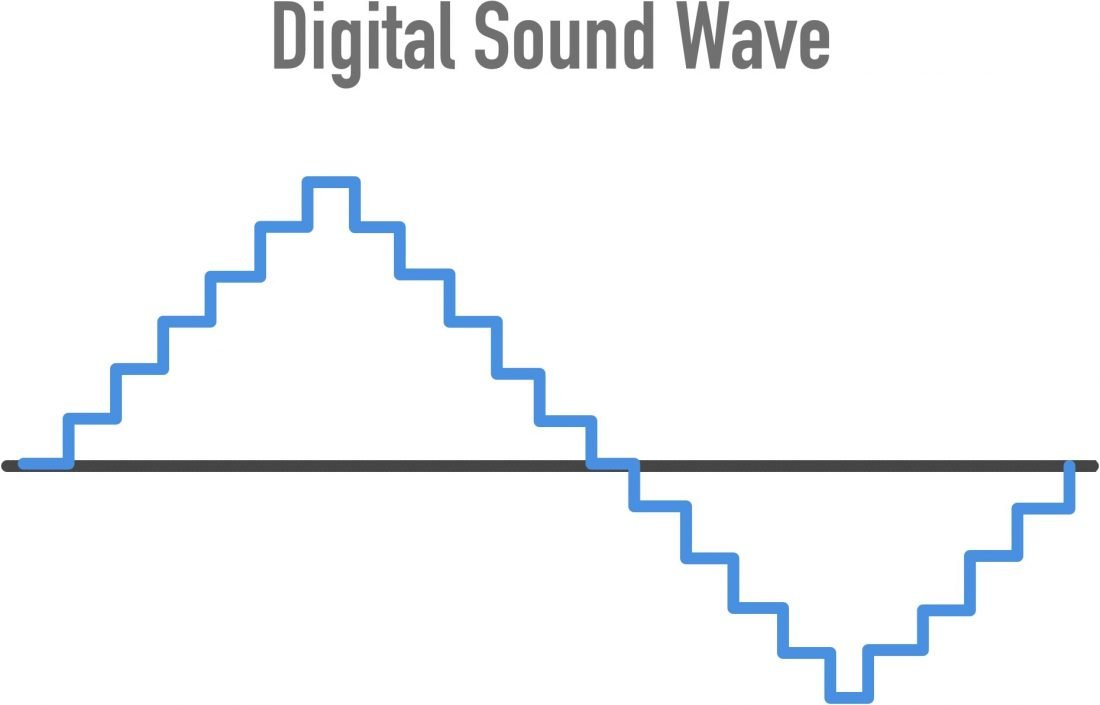
数字声波就像原始音频信号的快照。采样的声波越接近原始声波,数字声波的保真度就越高
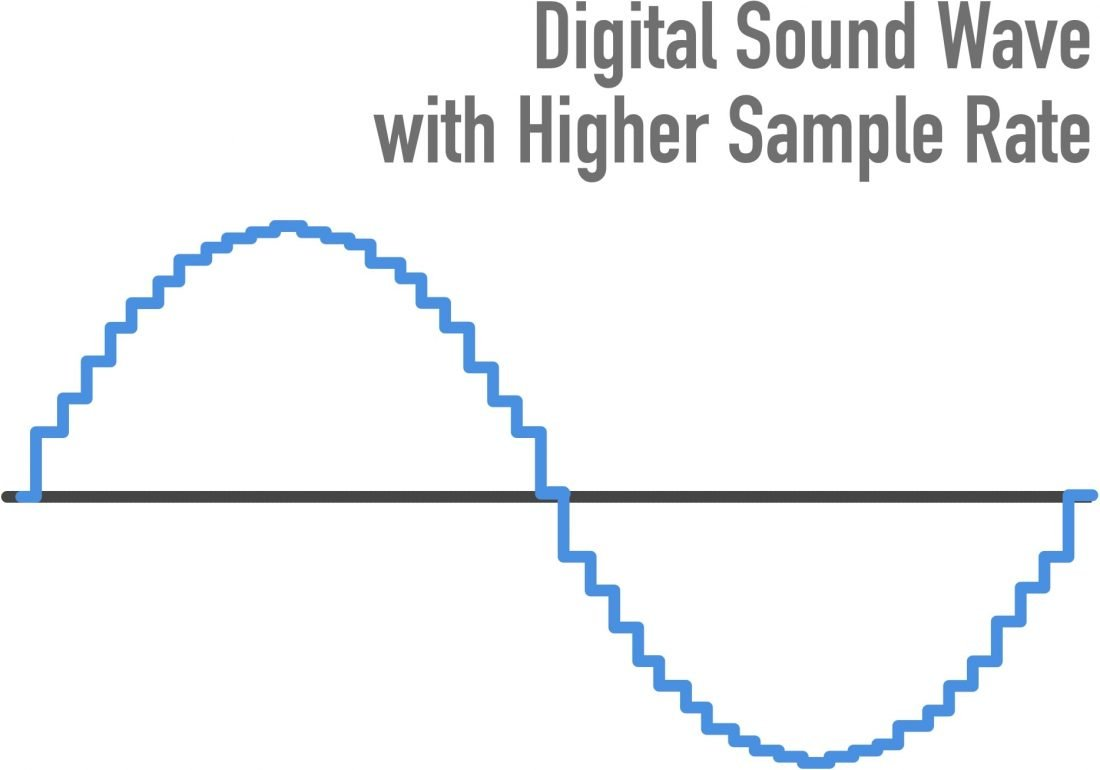
更高的采样率将使您更精确地捕获原始音频信号
采样率为什么是44.1KHz或更高?
这是由于低于所需最高频率的采样频率,信号得不到还原-奈奎斯特原理
需要所需最高频率的2倍及以上的采样频率才能如实还原信号,低于2倍所需采样频率将产生-混叠
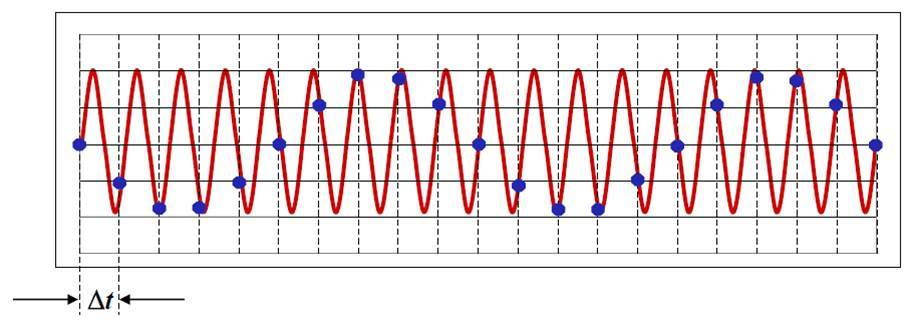
如上较长,蓝色点为实际采样点,红色为原始信号,这样原始高频信号变为了低频信号,混叠成低频了
44.1KHZ采样频率
根据奈奎斯特原理,使用每秒 44,100 个样本或 44.1kHz 的采样率可以准确再现大约 22kHz 的频率,即设备每秒记录44100次
常见采样率的其他示例是电话中的 8,000 Hz 和蓝光音轨的 96,000 Hz 到 192,000 Hz 之间的任何位置。在某些特殊情况下也使用 384,000 Hz 的采样率,例如在记录产生超声波的动物时。
位深
采样率是每秒记录声音的次数,对于用数字波形记录声音的方式来说,如果横轴是时间,想要出现完整的波形,那么就需要一个纵轴参数来为波形的“高度”进行设定。对于音频来说,这个高度信息,就是bit(位深)
位深度决定了可以存储多少信息。具有 24 位深度的采样可以存储更多细微差别,因此比具有 16 位深度的采样更精确。
所谓16bit,其真实含义是用16位的二进制数来表示采样点的电平(纵轴高度)
16 位:我们能够存储多达65,536级信息
24 位:我们能够存储多达16,777,216级信息
这与音乐的动态表现直接挂钩,24位比16们动态更大,精密度翻了1倍。
16 位数字音频的最大动态范围为 96 分贝,而 24 位深度将为我们提供最大 144 分贝
对于 44.1kHz 的采样率,16 位的位深度足以再现普通人的可听频率和动态范围,这就是它成为标准 CD 格式的原因

更高的采样位深HI-RES
尽管采样率和位深度没有限制,更高的采样率,更深的位深,如32位
更好的音质主要提供额外的空间、额外的动态容量、更小的失真等
有了额外的动态余量,音频工程师可以最大限度地减少(如果不能消除)过多噪音或削波的可能性,即声波基本上变得平坦并导致可听失真的情况
当输入的电信号不能完全用数字表示时,就会发生削波。当位深度较浅时,可能会发生这种情况。
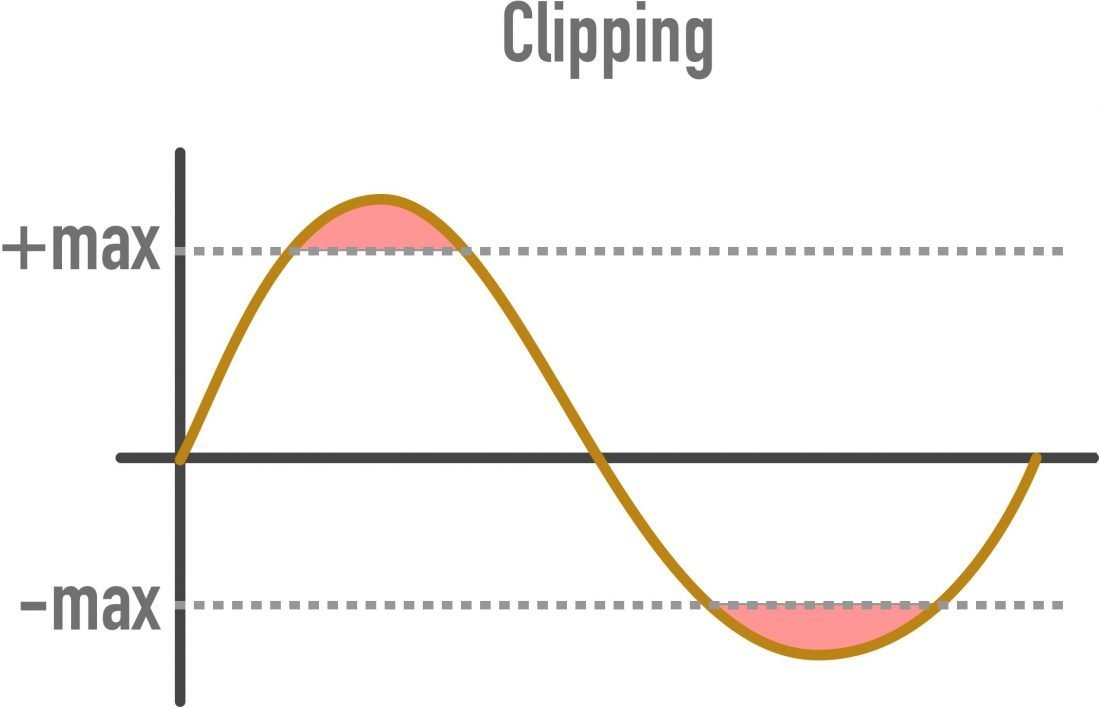
PS:由于专业音频设备可能的信号范围远大于普通人所能听到的,使用 24 位可以让音频专业人士干净利落地应用混音和母带处理中涉及的数千种效果和操作,为再现和分发做好准备.
存储空间
高保真度的录制会创建更大的文件大小,我们以顶尖的192kHz/24 对比CD
未压缩的比特率计算公式:采样频率比特深度通道
- 44.1kHz/16 位: 44,100 x 16 x 2 = 1,411,200 位/秒 ( 1.4Mbps )
- 192kHz/24 位:192,000 X 24 X 2 = 9,216,000 位/秒 ( 9.2Mbps )
加上时间值:
- 44.1kHz/16 位: 1.4Mbps * 360s = 504Mb ( 63MB )
- 192kHz/24bit:9.2MBps * 360s =3312Mb ( 414MB )
以 192kHz/24 位录制的音频将占用6.5 倍于以 44.1kHz/16 位采样的文件空间
PS:b表示计算机的bit,B表示Byte 字节,1B=8b
根据上面的原理,过高的采样没有意义,音乐本身更重要,因为一旦达到某个阈值,音质的边际提升就会越来越小,直到可以忽略不计。
PCM与DSD 编码
上面讲了基本的采样、量化与存储,这里就有个完全不同的编码方式,目前流行的高清HIFI音乐就是DSD,其它无损、有损均为PCM
- PCM(Pulse-Code Modulation,脉冲编码调制)
- DSD(Direct Stream Digital,直接比特流数字编码)
PCM为脉冲调制,每个采样点为独立的电平绝对值,采样点之间相互独立
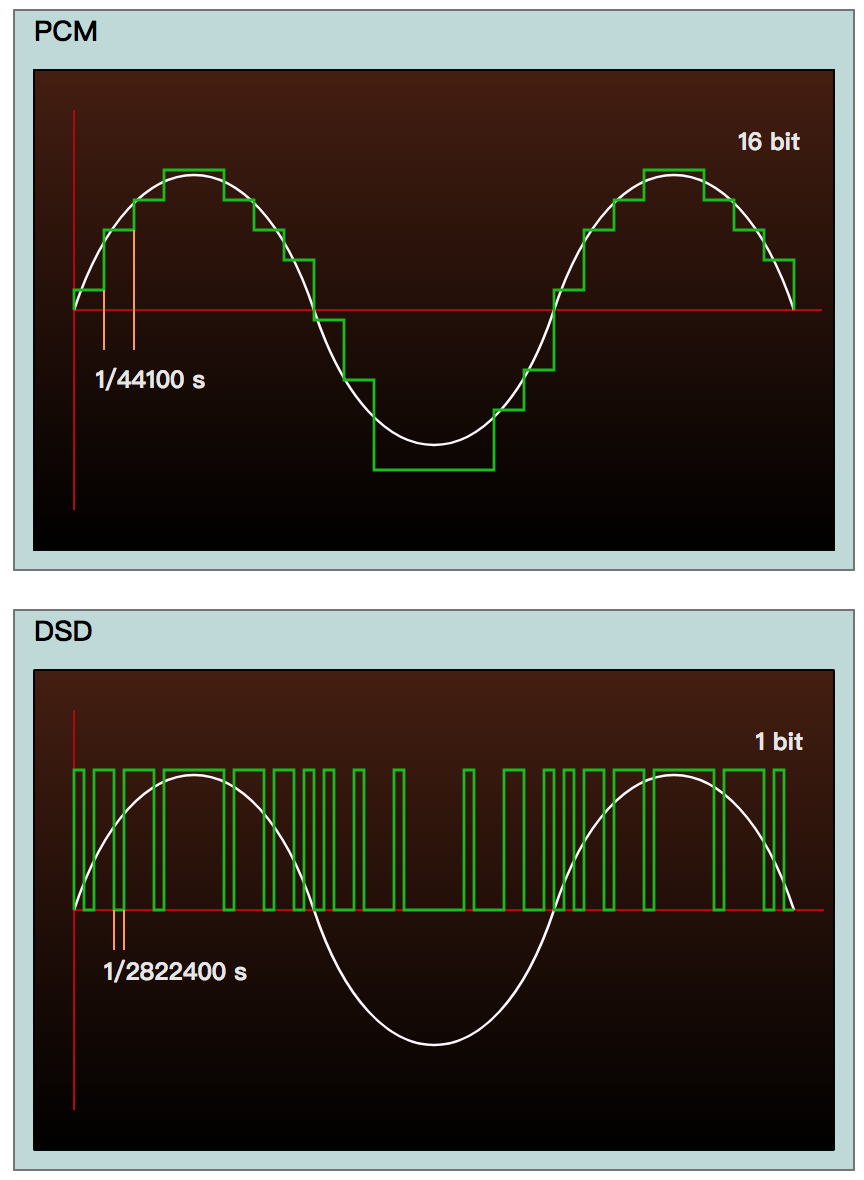
DSD为脉宽调制,连续不断的1bit取样,每个采样点只记录2个值,记录的内容则是相比上一个采样点记录数值的信号电平变化(增大还是减小),采样点之间数据互相关联,整首音频从开始到结束都可以视为是一个连贯、连续的整体
但DSD是以极高速度每秒采样,常规使用的DSD64,采样率是2.8224MHz,也就是每秒钟进行2824400次的采样记录,采样密度是CD的64倍。
形象理解,PCM 对以均匀间隔采样的模拟信号的幅度进行编码(有点像方格纸),并且每个样本都被量化为一系列数字步长内的最接近的值,量化中使用的位数越多和/或采样率越高,理论分辨率就越高。16 位 44.1KHz CD 每秒有 28,901,376 个采样点 (44,100 x 65,536)
而DSD当声音音压越大,这些取样点就越密,反之就越稀疏,在一密一疏之间,也就连续纪录了声音强弱的变化,而不是用多bit预先设定讯号强度的绝对值(16bit等于65,536个绝对值)。两相比较下来,DSD(脉冲密度调变)确实会比PCM(脉冲编码调变)更接近类比波型。
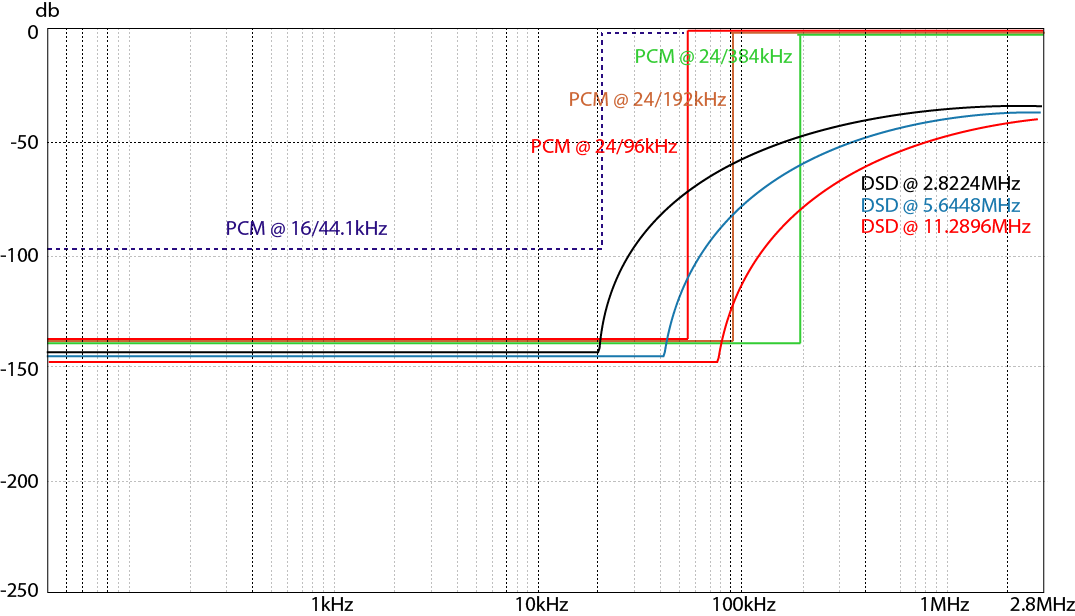
X轴是取样频率,Y轴是动态范围。可以得知特定取样率,在不同频段会出现高频噪讯。其中PCM格式是呈现一个断面,DSD则呈曲线升起,如果两种格式都不做数位滤波处理,PCM听起来是最不自然的。但PCM 解决之道很多,解决编码噪音、铃振等,而DSD没那么好处理。
DSD 和 PCM 都是“量化的”,这意味着数值被设置为接近模拟信号。DSD 和 PCM 都有量化误差。DSD 和 PCM 都有线性误差。DSD 和 PCM 都有量化噪声,需要在输出级进行过滤,换句话说,没有一个是完美的。
因此两者各有千秋,DSD技术的数据采样记录方向更为“线性”,时间密度也更高,采集到的数据量也先天较大,对时钟要求更高。因此现在不管从硬件、软件均以PCM为主流。DSD没法编辑、混合,不适合二次混音、编辑处理,要处理也需转为PCM再行编辑、混合和母带处理。
消费领域主要原生支持DSD解码的设备太少,大多数情况下只能先将DSD转换成PCM在进行播放,无法体验到DSD的优势
解决方法就是DOP,用PCM通道来传输DSD音频数据的外包装壳协议
目前DSD界面有DSD同轴输出(DSD/PCM SPDIF,DSD/PDM SPDIF是同样的,叫spdif),DSD AES/EBU(三根线,AES/EBU可以在三针信号中(XLR)传输两个声道)输出,DSD-DAC(不论界面还是同轴),都是通过DOP协议。DSD在PCM 上传输,是不会变成PCM音频数据的,DOP是个协议,是对DSD的一个包装。
音频格式
音频格式
目前音乐文件播放格式分为有损压缩和无损压缩两种
有损压缩顾名思义就是降低音频采样频率与比特率,输出的音频文件会比原文件小。另一种音频压缩被称为无损压缩,能够在100%保存原文件的所有数据的前提下,将音频文件的体积压缩的更小,而将压缩后的音频文件还原后,能够实现与源文件相同的大小、相同的码率。
无损格式,例如WAV,FLAC,APE,ALAC,WavPack(WV)
有损格式,例如MP3,AAC,Ogg Vorbis,Opus
无损压缩:
无损压缩主要是采用每家的压缩编码,不改变音质前提下压缩文件大小,主要为FLAC与APE
有损压缩:
将声音频号使用破坏性压缩,使用较少、有限的数据量来还原出接近原始的声音频号,以缩小保存声音频号所需的空间。
虽然每个有损音频压缩的格式压缩声音频号的方式都不太一样,但大致上都会优先保留20~20,000Hz频率范围内的声音频号,再根据心理声学来调整声音频号,尽量减少压缩过的声音频号和原本信号听起来的差异。
比特率
相同的压缩格式在固定的采样频率(Sampling Rate)下,所使用的比特率(Bitrate)是影响声音频号音质的主要因素。比特率的单位常使用「每秒多少比特(bps, bits per seconds)」来表示,也就是每一秒的声音频号使用了多少个比特来保存。
- 这有点像采样率,但测量的是比特数而不是样本数
- 比特率在播放/流媒体环境中比在录制环境中更常用
比特率愈高表示每秒可以保存的声音频号愈多,保存的声音频号愈多也就愈接近原始的声音频号,音质听起来自然会愈好。相反地,比特率愈少,表示每秒可以保存的声音频号愈少,必须要丢掉更多的原始声音频号才有办法保存,保存的声音频号就会和原始的声音频号愈差愈多,音质听起来自然会愈差
在音乐中,较高的比特率通常与较高的质量相关联。这是因为音频文件中的每一位都捕获了一段数据,我们可以用它来重现原始声音。但更高的比特率也意味着更大的文件大小,在网络传输或存储时就不利!同时存储时也需要更大空间。
我们看到要以串流方式传输以44.1kHz/16-bit录制的未压缩的歌曲,需要1.4Mbps的比特率,这是很大的带宽量。
不过现在存储界质与网络带宽1.4Mbps也不大,所以直接传输无损与存储无损也是完全OK的
虽然比特率愈高,可以使得压缩后的声音频号愈接近原始的声音频号,使用高比特率来保存声音频号,相对地需要更多的保存空间,更不利于网络传输。当高到一个程度之后,实际听起来就已几乎和原始的声音频号没有差异了,此时再增加比特率,只是多浪费保存空间而已。
6分钟 44.1kHz/16 位歌曲的未压缩文件大小将超过 63MB。
有损压缩就是解决这个问题的
比特率不一定是固定的
压缩声音信号时所使用的比特率,大致上可分为「固定比特率(CBR, Constant Bitrate)」和「变动比特率(VBR, Variable Bitrate)」两种。
通过无损或有损压缩,即可改变比特率,更适于传输与保存
如MP3压缩:128kbps*360秒=46080 kb/8=5.76MB 大小,更适合传输与存储
有损压缩
常用 MP3 OGG AAC等
综合对比后 Opus>Ogg=AAC>MP3
OPUS 为开放音频压缩编码格式,为比较新的一个,显著特点是非常低的延迟,更好的压缩率,因此串流可以选择OPUS,当然也可以是主流的MP3
每种压缩编码格式都有其特点及适用环境,比如不同的比特率下品质不同、不同的适用环境不同
只要比特率足够高,Ogg可以说是在这个不同采样频率的测验中音质最好的有损音频压缩格式
AAC 也很好,新颖的Opus格式在48kHz的采样频率中表现也非常优异。
无损压缩
WAV 音频格式是最接近无损的一种音乐格式,换言之与CD比较就是无损的,Adobe Audition 系列软件默认就是wav,也方便编辑、混音与后期处理,几乎任何播放器都能播放
文件大小(Byte) = (取样频率 * 取样位数 * 声道) * 时间 / 8,就是我们上面讲到的计算方式,是未经压缩的音频,非常占用空间
有损压缩是丢掉很多人耳不敏感的,以及通过听觉、心理学等让你听起来是真实的原来的音乐,这种有损压缩算法往往都是不可逆的。
无损压缩常用的是APE与FLAC,APE\ FLAC\ WAV, 均可还原出相同的音频数据
APE是双精度型浮点数字算法,FLAC则是整型数字算法
一般来说APE压缩后的体积更小些,但是APE文件并不具备错误处理的能力,一旦文件损坏,数据就很有可能会丢失,导致无法播放
同时FLAC是开源的,支持的设备、软件多,FLAC 可以获取高解码速度,因为他的算法不复杂,并且有助于数十种消费电子设备对其的支持,因此推荐FLAC 格式
两者都可以压缩百分之五十几,利于存储
- 解码速度:APE<FLAC<WAV
- 播放音质:APE=FLAC<WAV
但他们与DSD是完全不同的,转换上述格式,通常用foobar,播放也一样,DSD需要专门的播放器或插件

主流表现对比

FLAC 详细对比报告 https://xiph.org/flac/comparison.pdf
评论区